I'm setting up CRR on two buckets, one new, and one existing - which already contains files
When you enable cross-region replication on an existing bucket, it doesn't copy existing files from the source to the target bucket - it only copies those objects created or updated after the replication was enabled. We need to copy the original files manually using the AWS CLI.
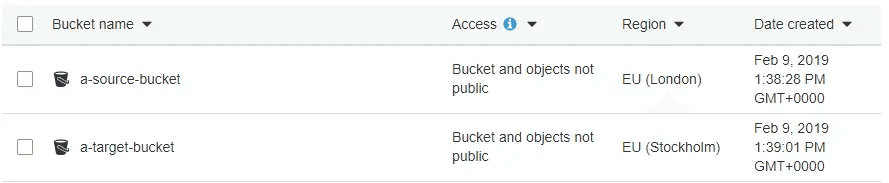
We're using a-source-bucket as the bucket containing the original files, and a-target-bucket as the empty bucket that's going to receive the copy.
What's in the source bucket?
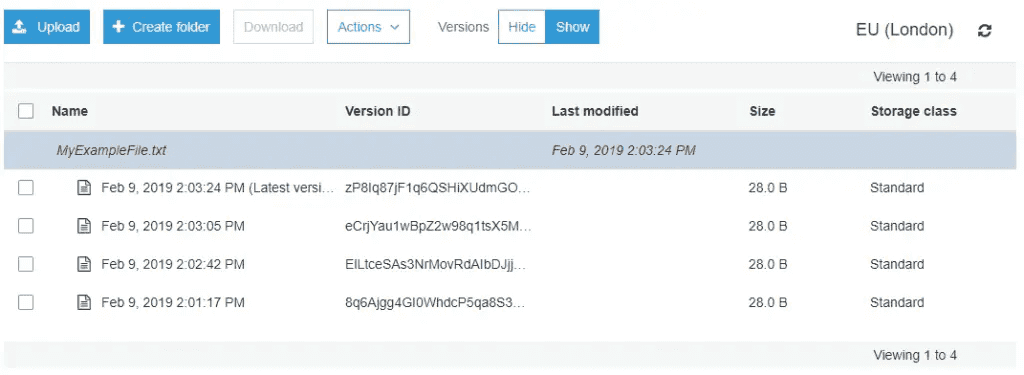
The source contains 1 file, with 4 versions of that file
Copying across the files to our target bucket
After setting up the cross-region replication for a-source-bucket > a-target-bucket, we need to copy the existing file.
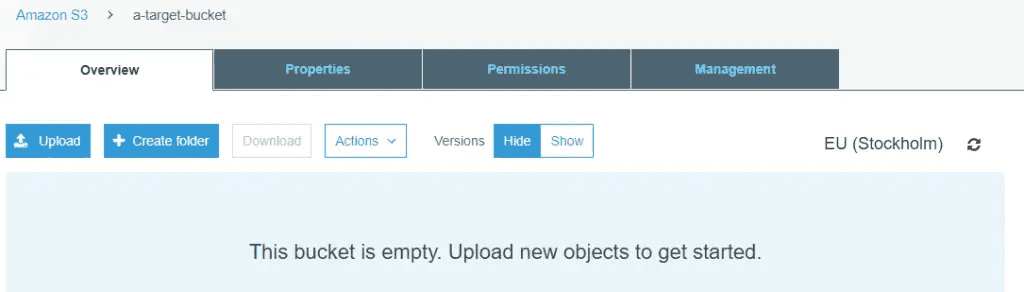
The target bucket is empty
In the AWS CLI, we can list our buckets and then run a cp command to copy the content across.
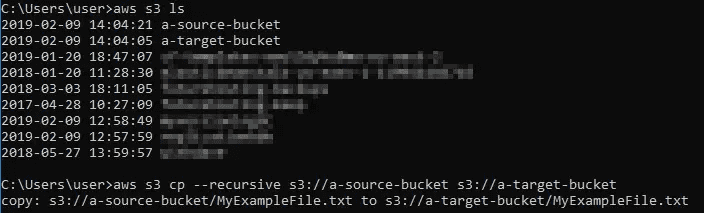
Listing the buckets available to our user, then copying the content
> aws s3 ls
2019-02-09 14:04:21 a-source-bucket
2019-02-09 14:04:05 a-target-bucket
> aws s3 cp --recursive s3://a-source-bucket s3://a-target-bucket
copy: s3://a-source-bucket/MyExampleFile.txt to s3://a-target-bucket/MyExampleFile.txt
The result of the copy is that our target bucket has a copy of the latest version of the file from our source bucket, and as cross-region replication is enabled, all future files will be copied too (and versioned).
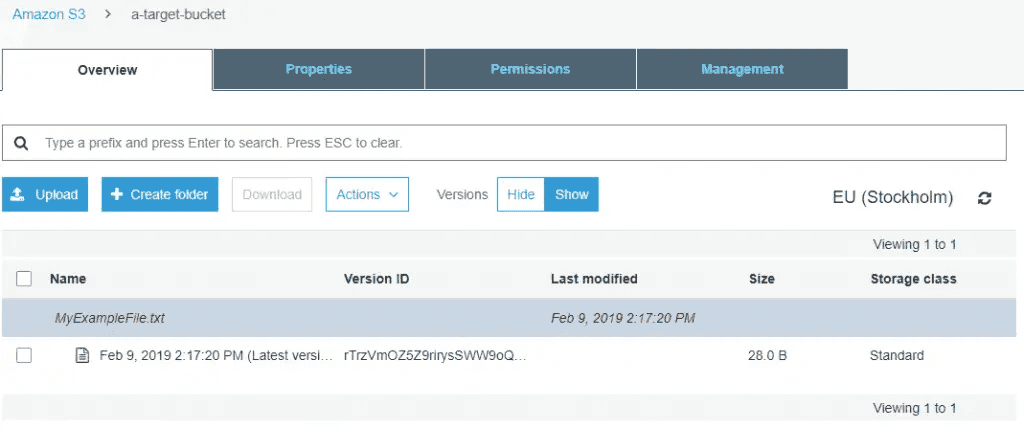
The file has been copied to the target bucket, but note this does not transfer previous versions from the source bucket
What if I've already got files in my target bucket and it's out of sync with the source?
If you don't wish to empty the bucket and start with a fresh copy, then consider using the S3 sync command.
What if I want to copy the version history?
You'll need to script this, as although the versions are accessible they won't be moved by a standard cp command.
What about if my bucket is huge?
Using this approach provides acceptable transfer speeds, but if you're moving thousands of files, or TBs of data it may be faster to use S3DistCp. This spins up an EMR cluster to copy files in parallel, significantly reducing the manual copy time and supporting millions of objects through scaling the cluster size.